
Mitigating Catastrophic Forgetting using Context-Dependent Learning
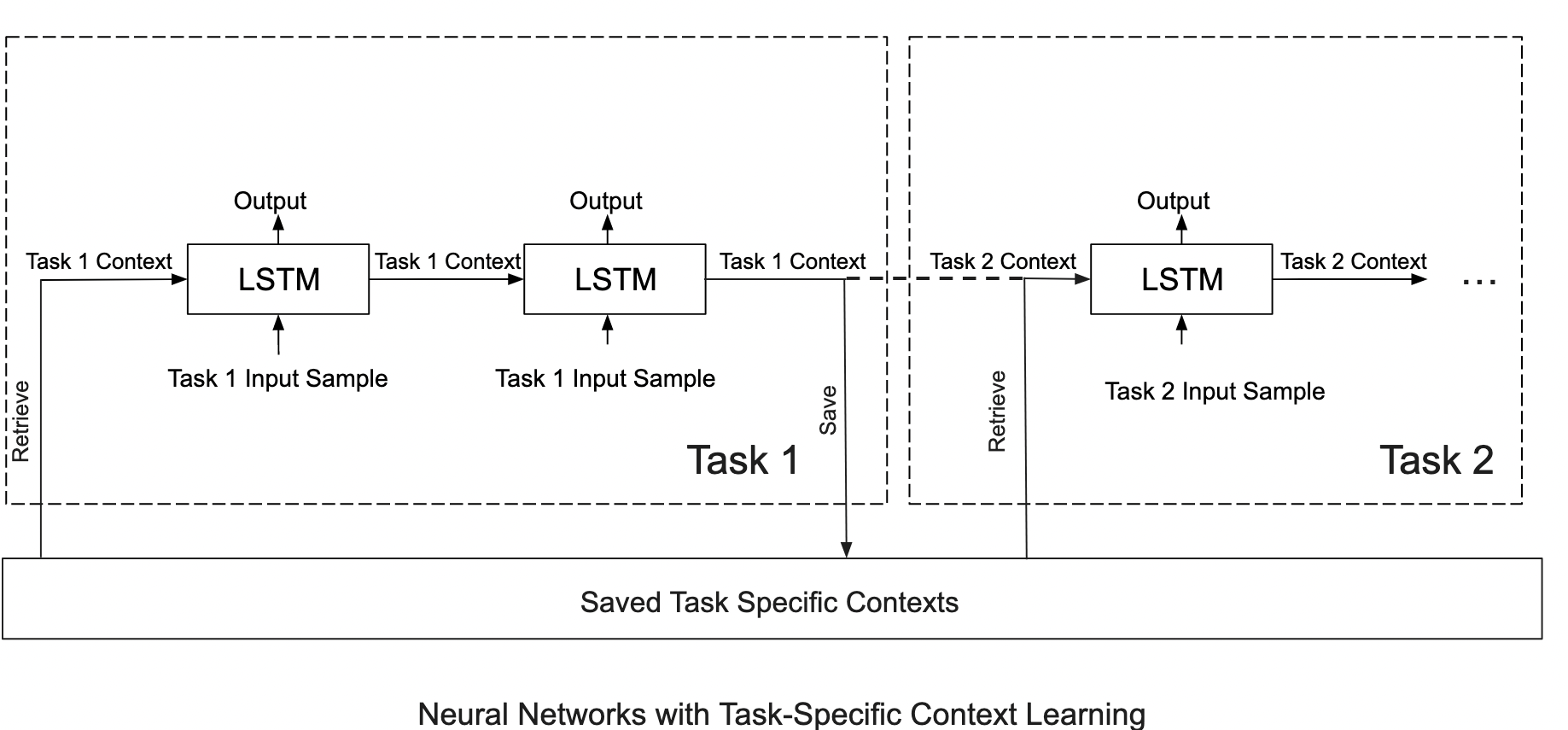
Catastrophic Forgetting is a fundamental challenge faced by all systems that learn online. We propose leveraging the cognitive inspiration of context-dependent learning to reduce forgetting in a resource-efficient manner. Read more
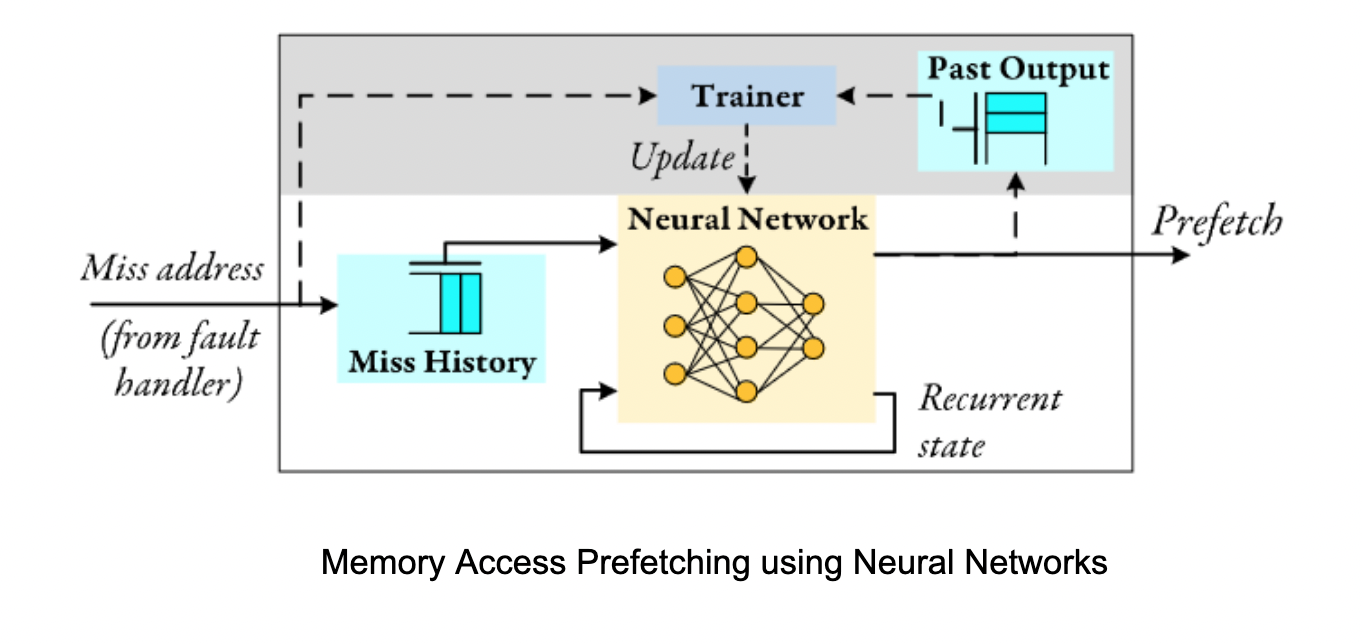 We study the potential of leveraging human brain inspired principles of learning to build resource-efficient, accurate and adaptable ML solutions for memory management, specifically, memory access prefetching in computer systems.
We study the potential of leveraging human brain inspired principles of learning to build resource-efficient, accurate and adaptable ML solutions for memory management, specifically, memory access prefetching in computer systems. 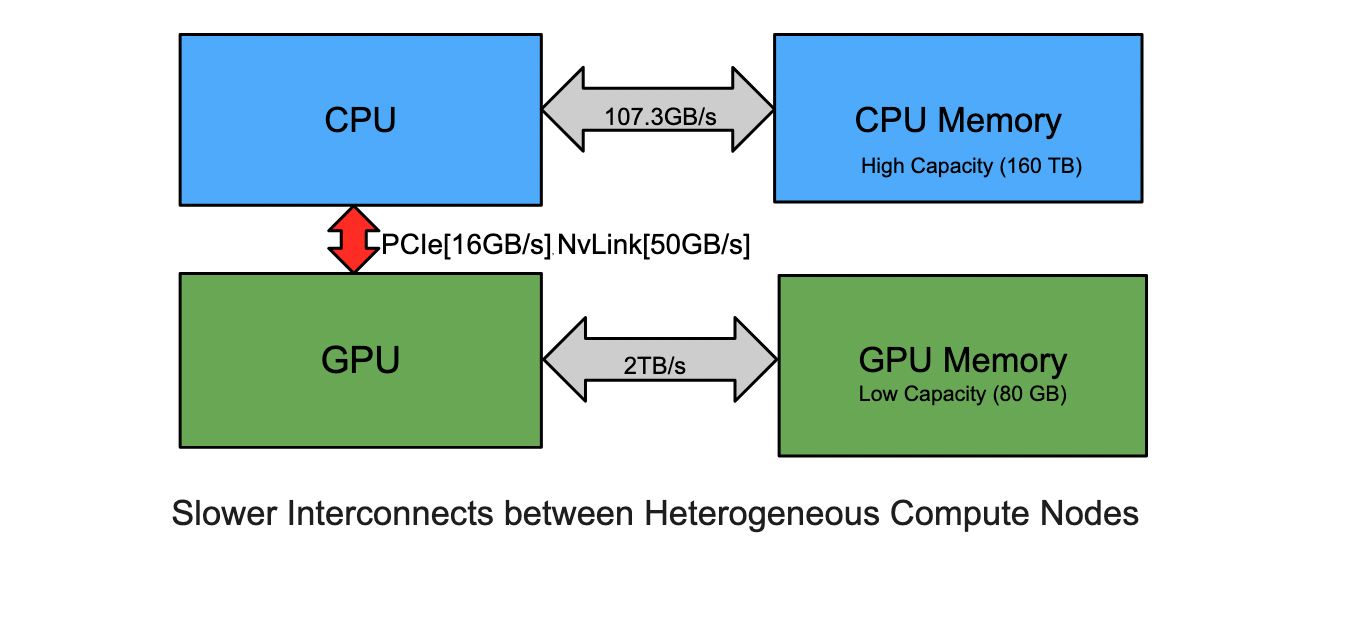 Computer systems are becoming increasingly heterogeneous. In heterogeneous systems, accelerators such as GPUs have lower memory capacity but higher bandwidth than CPUs. Furthermore, the interconnects between the heterogenous nodes are slower, slowing down memory transfer. To reduce these slow memory transfers, it is important to keep the data close to the node where it will be required.
Computer systems are becoming increasingly heterogeneous. In heterogeneous systems, accelerators such as GPUs have lower memory capacity but higher bandwidth than CPUs. Furthermore, the interconnects between the heterogenous nodes are slower, slowing down memory transfer. To reduce these slow memory transfers, it is important to keep the data close to the node where it will be required. 
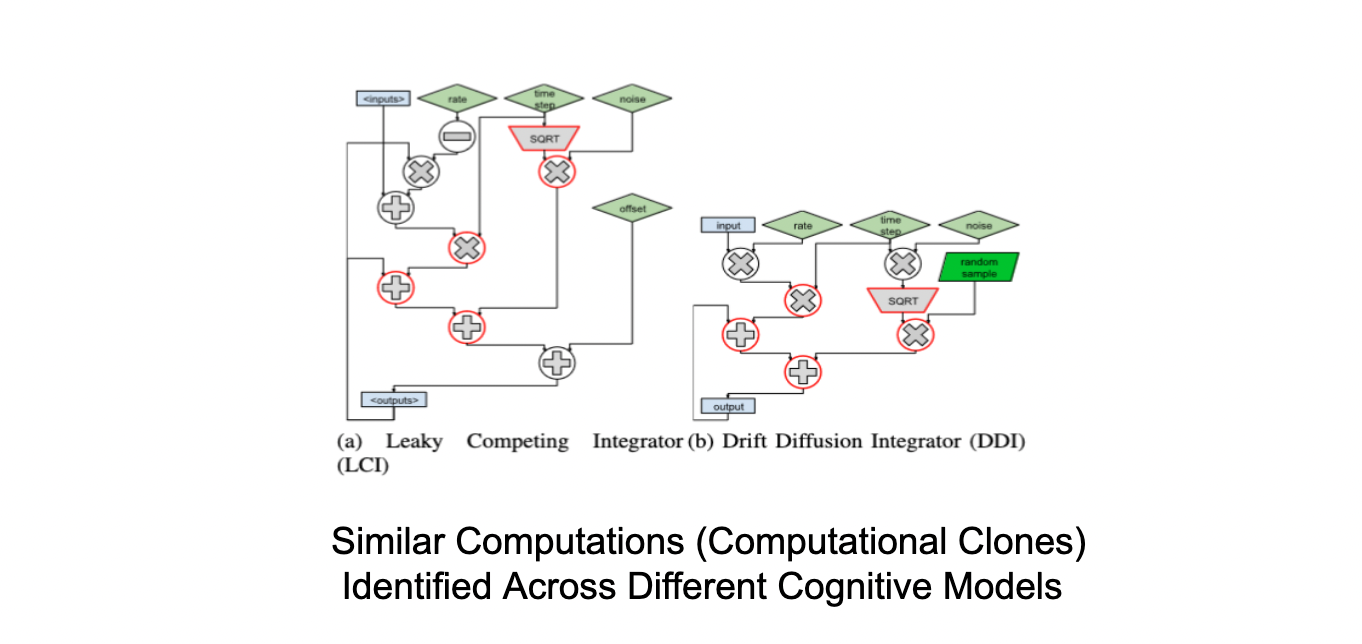 Cognitive models are time-consuming to create because they require the combination of numerous types of computational tasks. They perform poorly because they are typically written in high-level languages such as Python. In this work, we present Distill, a domain-specific compilation tool for accelerating cognitive models while still allowing cognitive scientists to develop models in flexible high-level languages.
Cognitive models are time-consuming to create because they require the combination of numerous types of computational tasks. They perform poorly because they are typically written in high-level languages such as Python. In this work, we present Distill, a domain-specific compilation tool for accelerating cognitive models while still allowing cognitive scientists to develop models in flexible high-level languages.