Page Not Found
Page not found. Your pixels are in another canvas. Read more

A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Page not found. Your pixels are in another canvas. Read more
About me Read more
This is a page not in th emain menu Read more
Published:
This post will show up by default. To disable scheduling of future posts, edit config.yml and set future: false. Read more
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool. Read more
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool. Read more
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool. Read more
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool. Read more
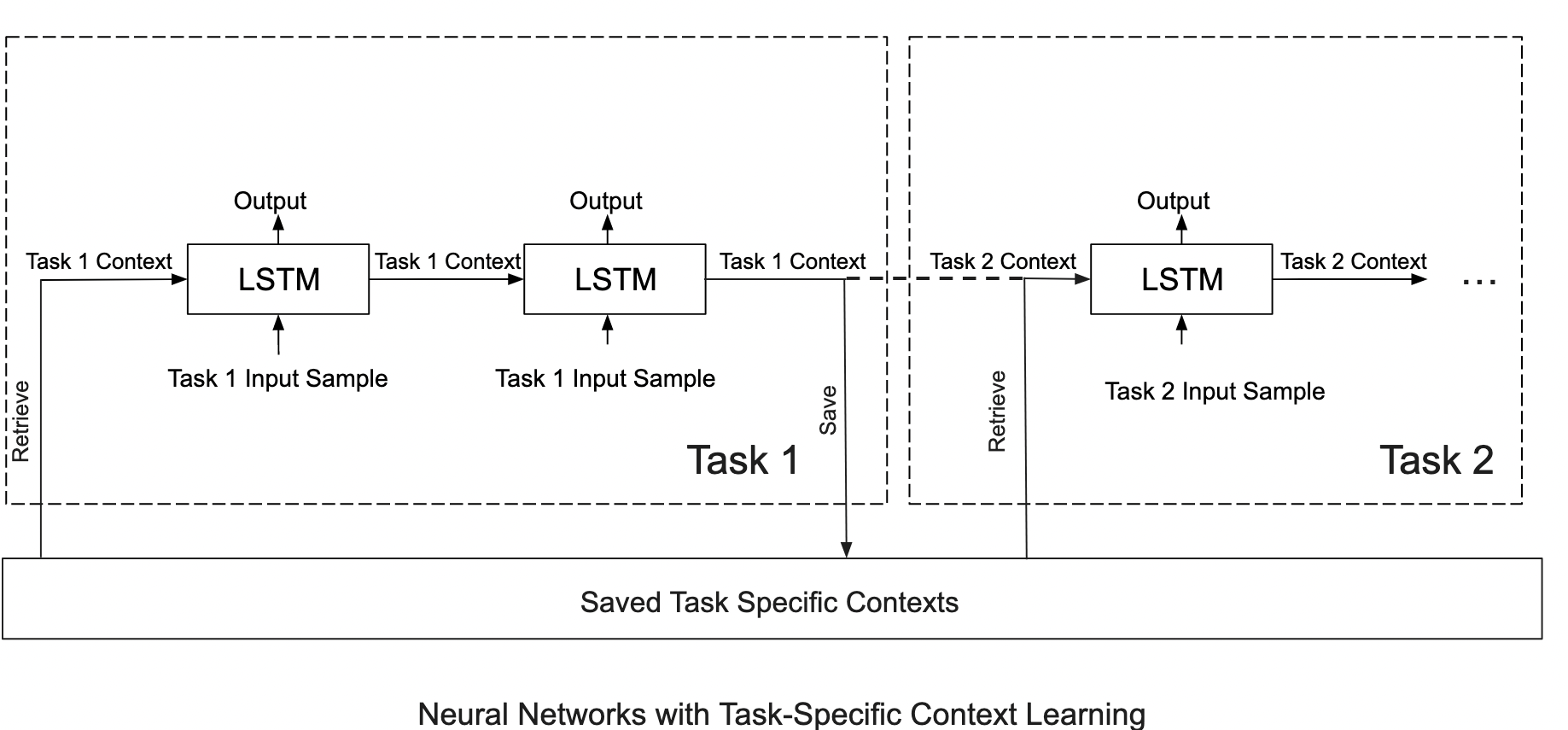
Catastrophic Forgetting is a fundamental challenge faced by all systems that learn online. We propose leveraging the cognitive inspiration of context-dependent learning to reduce forgetting in a resource-efficient manner. Read more
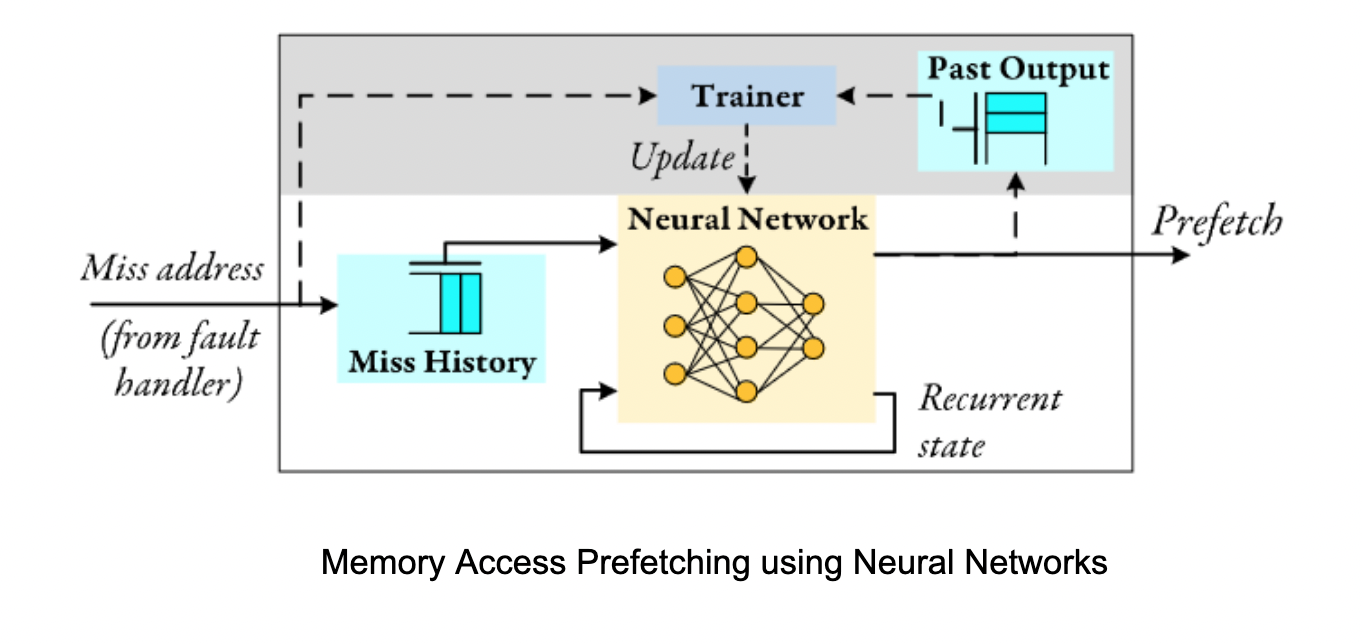 We study the potential of leveraging human brain inspired principles of learning to build resource-efficient, accurate and adaptable ML solutions for memory management, specifically, memory access prefetching in computer systems. Read more
We study the potential of leveraging human brain inspired principles of learning to build resource-efficient, accurate and adaptable ML solutions for memory management, specifically, memory access prefetching in computer systems. Read more
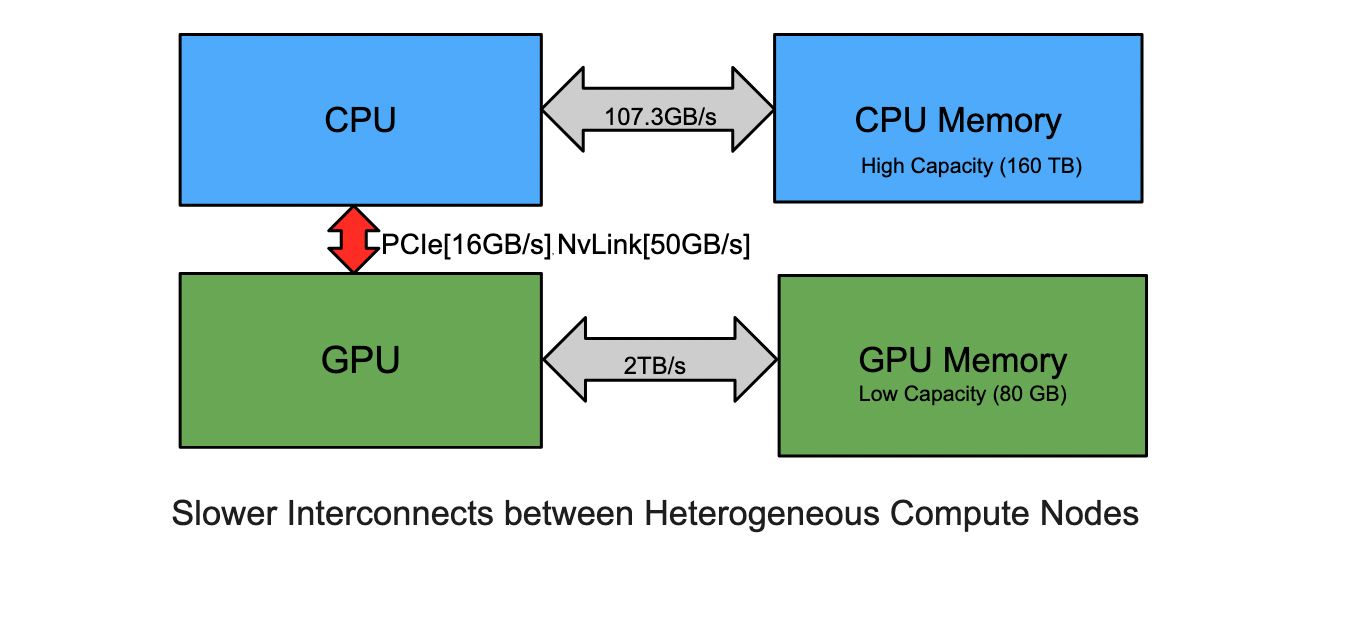 Computer systems are becoming increasingly heterogeneous. In heterogeneous systems, accelerators such as GPUs have lower memory capacity but higher bandwidth than CPUs. Furthermore, the interconnects between the heterogenous nodes are slower, slowing down memory transfer. To reduce these slow memory transfers, it is important to keep the data close to the node where it will be required. Read more
Computer systems are becoming increasingly heterogeneous. In heterogeneous systems, accelerators such as GPUs have lower memory capacity but higher bandwidth than CPUs. Furthermore, the interconnects between the heterogenous nodes are slower, slowing down memory transfer. To reduce these slow memory transfers, it is important to keep the data close to the node where it will be required. Read more
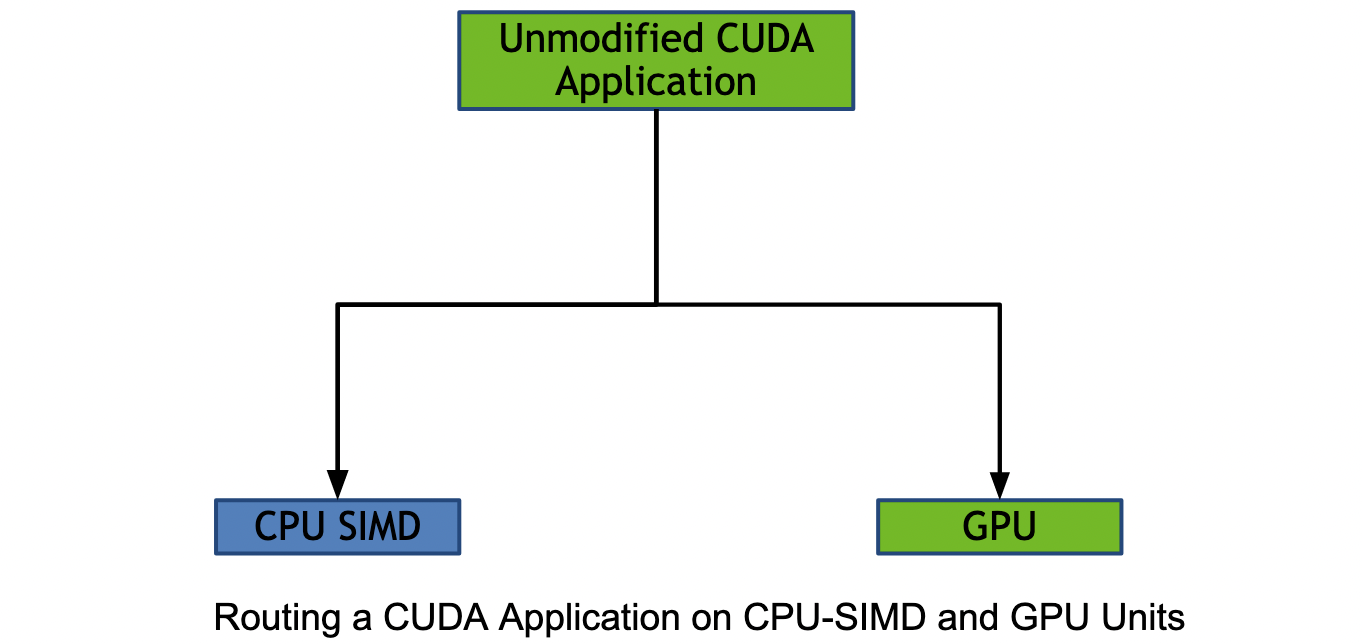
Today’s systems are increasingly heterogeneous. Accelerators such as GPUs and CPUs should all be viewed as available thread-pools capable of running the application at hand. The goal is not to outperform a discrete accelerator such as a GPU. The goal is to reduce idle system times, which leads to improved power efficiency and throughput for the entire heterogeneous ecosystem. Read more
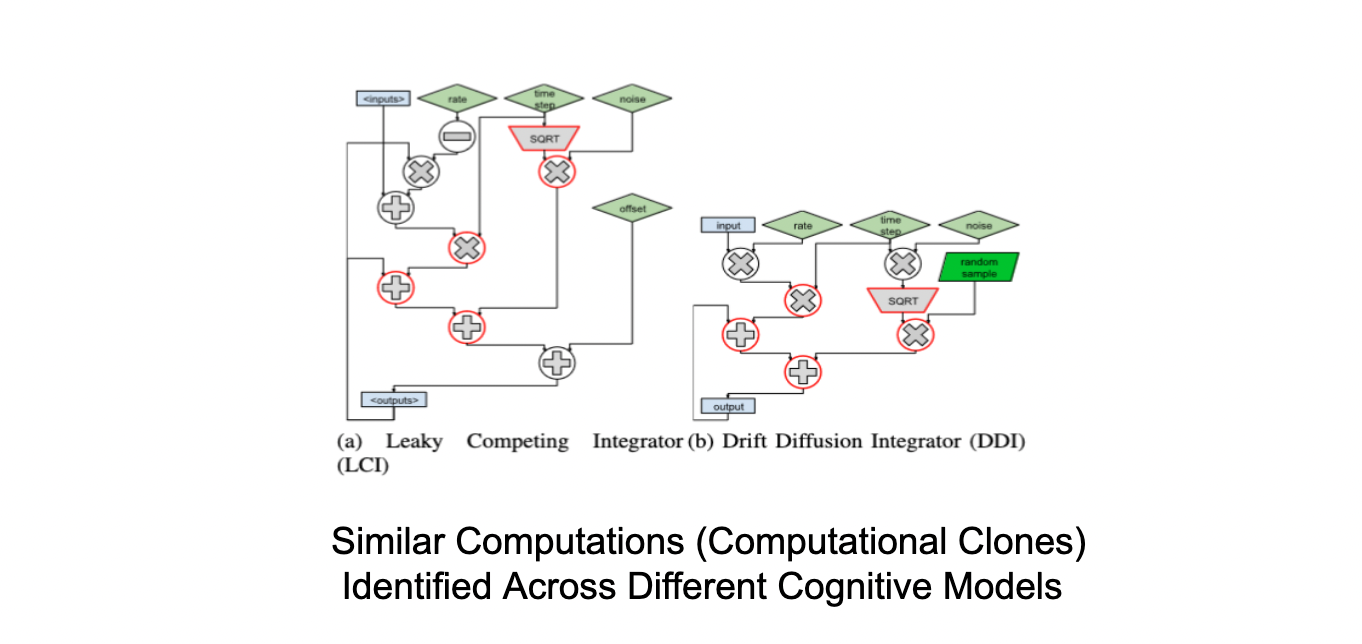 Cognitive models are time-consuming to create because they require the combination of numerous types of computational tasks. They perform poorly because they are typically written in high-level languages such as Python. In this work, we present Distill, a domain-specific compilation tool for accelerating cognitive models while still allowing cognitive scientists to develop models in flexible high-level languages. Read more
Cognitive models are time-consuming to create because they require the combination of numerous types of computational tasks. They perform poorly because they are typically written in high-level languages such as Python. In this work, we present Distill, a domain-specific compilation tool for accelerating cognitive models while still allowing cognitive scientists to develop models in flexible high-level languages. Read more
Published in CGO, 2022
Recommended citation: https://dl.acm.org/doi/abs/10.1109/CGO53902.2022.9741278
Published in Arxiv, 2023
Recommended citation: https://arxiv.org/abs/2305.17244
Published in Arxiv, 2023
Recommended citation: https://arxiv.org/abs/2305.17244
Published in , 2021
Recommended citation: https://scholar.google.com.hk/citations?view_op=view_citation&hl=it&user=vuz_F7IAAAAJ&citation_for_view=vuz_F7IAAAAJ:u-x6o8ySG0sC
Published:
Depending on the application, the nature of the optimization passes within the compiler varies. We developed a compiler optimization generator, which enables compiler researchers and engineers to specify data flow equations for the required optimization. The optimization generator uses these equations to build the desired compiler optimization passes, which it then inserts on the fly into the compiler. Read more
Published:
Low-speed interconnects serve as a fundamental issue to CPU-GPU systems. This means that if the GPU kernel offload costs are greater than the computation time, it makes no sense to migrate jobs to the GPU. We studied the potential of offloading unmodified CUDA source code to CPU SIMD units if they were available along with GPUs. This functionality was implemented in the system software layer as a CUDA driver shim that was transparent to the application developer. We demonstrated 1.5X performance improvements over a pure-CPU SIMD execution and 1.3X improvements over a pure-GPU execution of data center applications. Read more
Published:
With the increasing volume of data and the availability of various accelerators, it is critical to maximize system utility in heterogeneous systems. The fact that companies such as NVIDIA are acquiring Mellanox, Intel is acquiring Altera, and AMD is acquiring Xilinx demonstrates industry awareness of the importance of maximizing system utilization in heterogeneous architectures by leveraging all available compute power from different processors in addition to traditionally targeted processors for specific workloads. We foresee a hardware-agnostic system in which any application, regardless of its conventional hardware target, can execute on any hardware substrate. We demonstrate this by running CUDA programs that were previously only executed on GPUs on CPU SIMD units alongside GPU cores. The challenge here is to retain programmability by leaving the application source code alone. This mapping should be done transparently to the application developer, with comparable performance to make the effort worthwhile while supporting all degrees of parallelism. This vision also has its own set of memory management difficulties, which we go through in depth. For batched workloads that mirror data center conditions, we achieved 1.5X greater performance than a pure CPU-SIMD setup and 1.3X better performance than a pure GPU setup. This demonstrates the potential for characterizing workloads and routing to the appropriate hardware substrate. Read more
Published:
Today’s systems are heterogeneous. When we look at CPU-GPU systems, we can see that CPUs have more memory capacity and lower bandwidth than GPU systems. Furthermore, limited bandwidth interconnects make overall data flow between system components difficult to optimize. As a result, it is critical to position the data as close to the compute unit as possible and, if possible, to decrease the number of migrations between different system components. The majority of migration costs are related to page fault latency and slow interconnects. As a result, it is critical that we decrease the number of page faults and are aware of what is evicted from GPU memory that may cause page faults later. In other words, we don’t want to evict data only having to migrate it again. This is especially essential in workloads when data is reused. My research focused on enhancing the performance of the present Unified Virtual Memory (UVM) eviction mechanism, which performs miserably in workloads with data reuse. This is because the existing policy does not take access information into account. I created an eviction policy that attributes access patterns and access information of a workload to prevent evicting data that can be used in the near future. We were effective in accounting for access information and avoiding the removal of data that will be required in the near future. As a result, the number of page faults is reduced. This is in contrast to the current policy, which simply evicted data that was least recently migrated without taking into account its usage pattern. We were able to demonstrate two orders of magnitude speedup in terms of end-to-end application time when the GPU memory was oversubscribed i.e. was full and required evictions. This talk was given as an end of internship talk for Nvidia. Read more
Introduction to Systems Programming, Yale University, 2021
Introduction to Systems Programming, Yale University, 2022
Introduction to Systems Programming, Yale University, 2022