
Hardware Agnostic Parallel Application Deployment
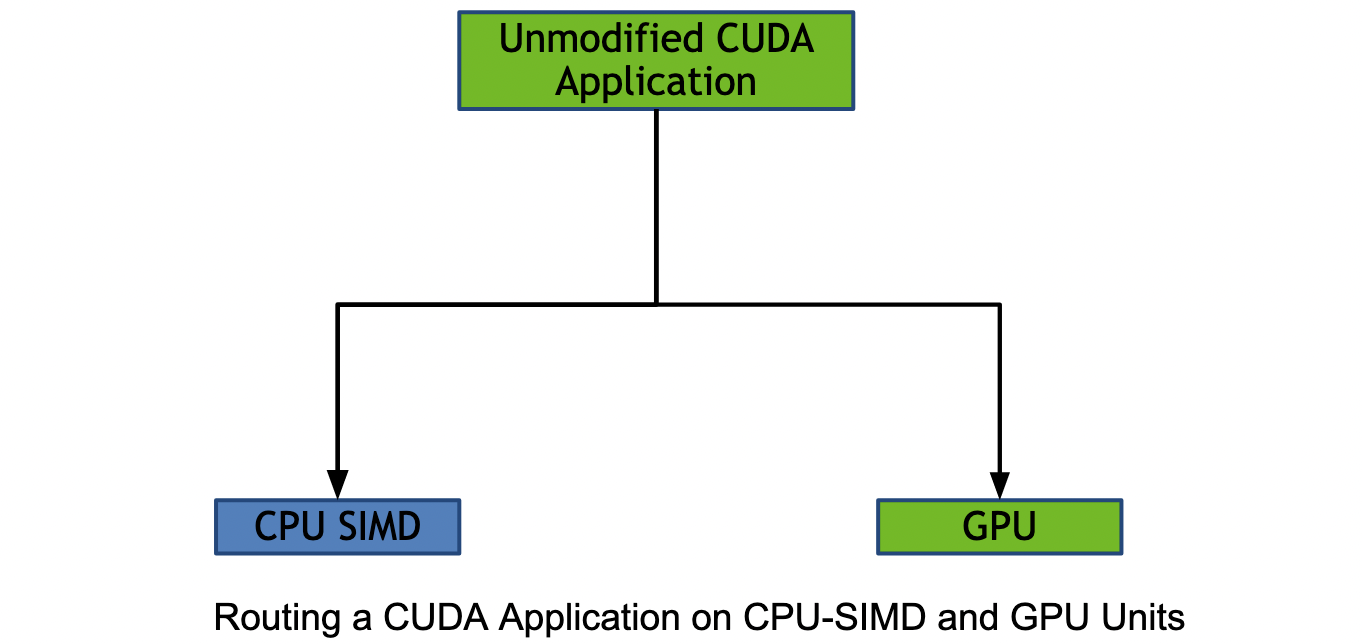 Today's systems are increasingly heterogeneous. Let us consider a system with CPUs and GPUs. Compute-intensive or highly parallel parts of the application code are traditionally dispatched on a GPU while the sequential parts of the application are run on a CPU. We are now moving towards a unified architecture, i.e., CPUs and GPUs should co-exist as first-class compute citizens on the same system. On these unified architectures, the CPU should not merely be the offloader of tasks to the other system components such as the GPU. It would be beneficial if, GPUs and CPU SIMD units are all viewed as equally available compute-pools capable of running the application at hand. The goal is not to outperform a discrete accelerator such as a GPU. The goal is to reduce idle system times, which leads to improved power efficiency and throughput for the entire heterogeneous ecosystem. All of this must be accomplished without impairing the application developer's programmability, i.e. re-routing compute parts of an application on traditionally targeted or non-targeted hardware should occur under the application's hood. For the application developer such as a CUDA application developer, a CUDA program should still look as before. We achieve this by implementing the CPU-GPU re-routing from within the GPU driver.
Today's systems are increasingly heterogeneous. Let us consider a system with CPUs and GPUs. Compute-intensive or highly parallel parts of the application code are traditionally dispatched on a GPU while the sequential parts of the application are run on a CPU. We are now moving towards a unified architecture, i.e., CPUs and GPUs should co-exist as first-class compute citizens on the same system. On these unified architectures, the CPU should not merely be the offloader of tasks to the other system components such as the GPU. It would be beneficial if, GPUs and CPU SIMD units are all viewed as equally available compute-pools capable of running the application at hand. The goal is not to outperform a discrete accelerator such as a GPU. The goal is to reduce idle system times, which leads to improved power efficiency and throughput for the entire heterogeneous ecosystem. All of this must be accomplished without impairing the application developer's programmability, i.e. re-routing compute parts of an application on traditionally targeted or non-targeted hardware should occur under the application's hood. For the application developer such as a CUDA application developer, a CUDA program should still look as before. We achieve this by implementing the CPU-GPU re-routing from within the GPU driver. 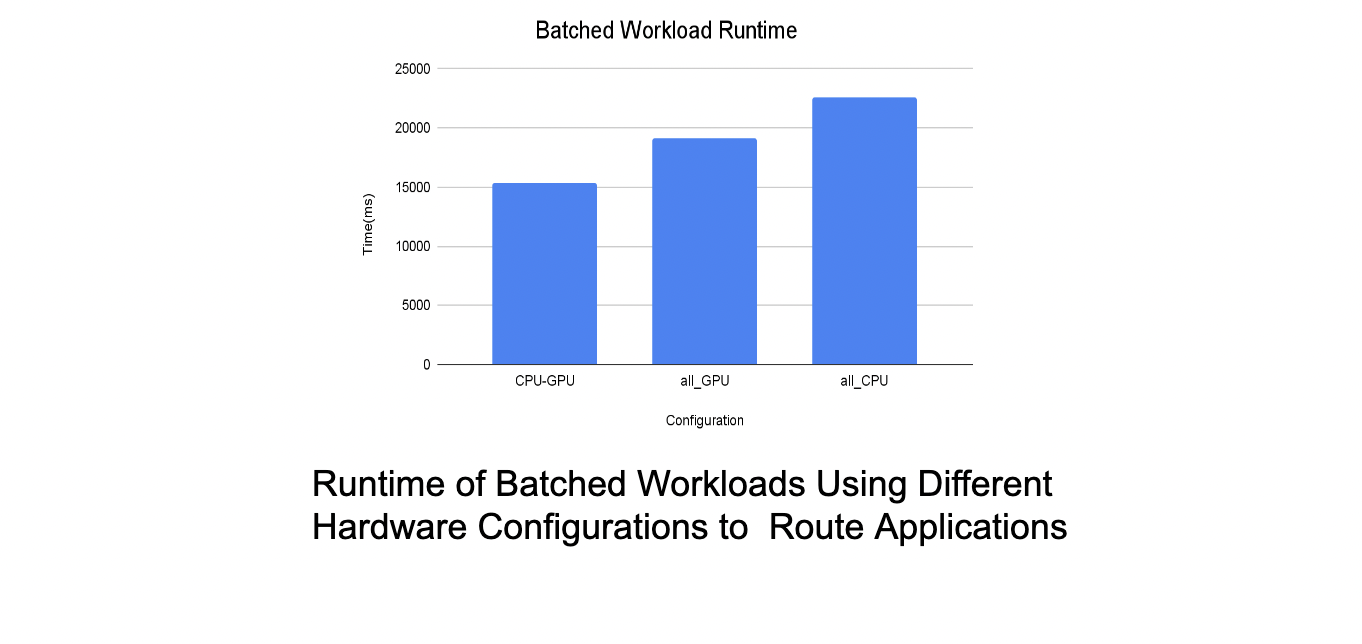
By running batched applications on an all-CPU, all-GPU, and CPU-GPU configuration, we simulated data center workloads. We dispatched some applications from the same batch on the CPU-SIMD units and some on the GPU in the CPU-GPU configuration. This was preceded by workload characterization to determine which applications perform better on the CPU-SIMD vs the GPU by comparing the costs of offloading compute to the GPU and then performing the computation vs the cost of performing the computation on the CPU's SIMD units itself. We see in the graph above, that the batched workload performs better on the CPU-GPU configuration. In the initial prototype we saw a performance improvement of 1.5 times compared to using only CPU-SIMD units and an improvement of 1.3 times compared to using only GPUs for the batched workloads. These findings confirm that parallelizing applications on CPU-SIMD and GPU improves batch turnaround times and system utilization in datacenters. We achieve this without affecting the application's programmability i.e. a CUDA program still looks the same from the CUDA programmer's perspective.
This talk was based on the work done as a part of the internship at Nvidia Research in the summer of 2021.