
Distill: Domain-Specific Compilation for Cognitive Models
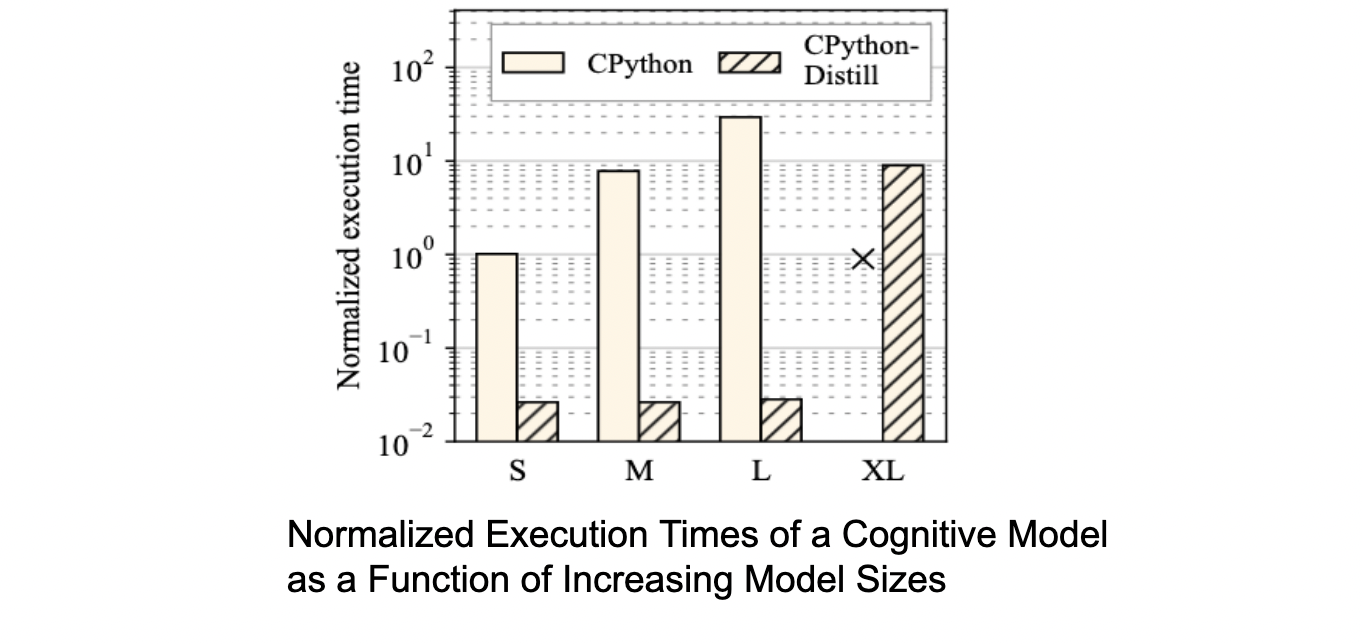 Distill uses domain-specific knowledge to compile Python-based cognitive models into LLVM IR, carefully stripping away features like dynamic typing and memory management that add performance overheads without being necessary for the underlying computation of the models. The net effect is a performance improvement in model execution by Distil over state-of-the-art techniques using Pyston and PyPy.
Distill uses domain-specific knowledge to compile Python-based cognitive models into LLVM IR, carefully stripping away features like dynamic typing and memory management that add performance overheads without being necessary for the underlying computation of the models. The net effect is a performance improvement in model execution by Distil over state-of-the-art techniques using Pyston and PyPy. 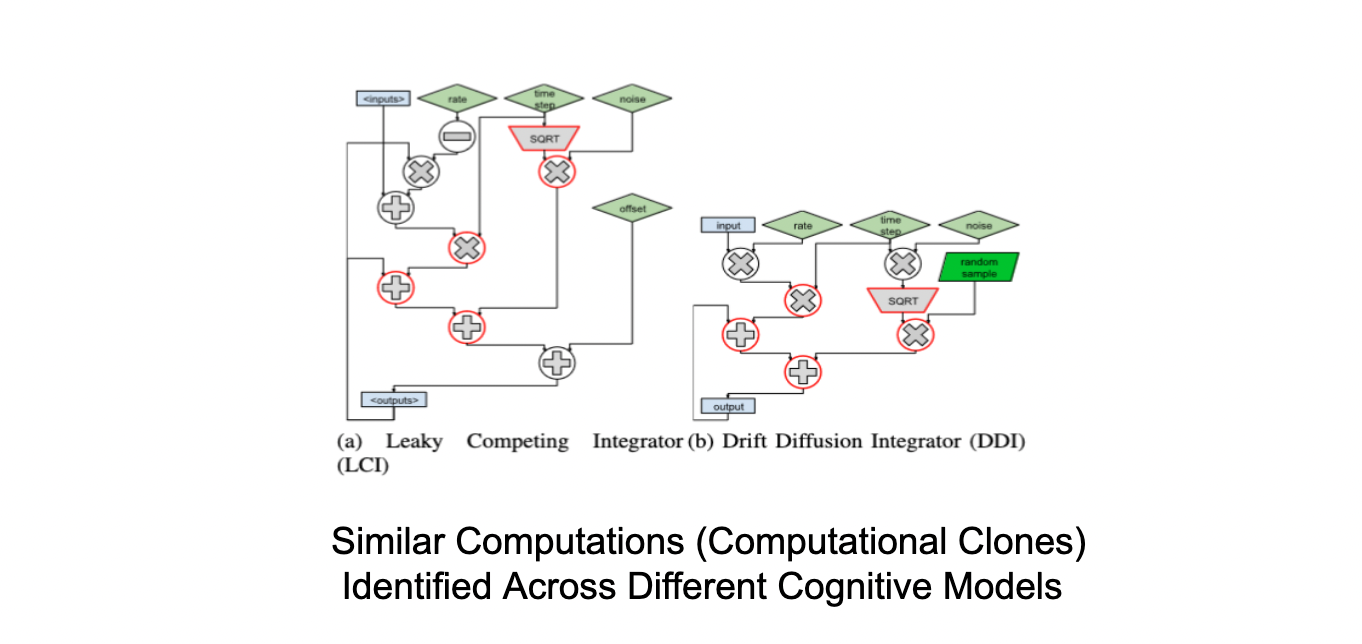 Distill also repurposes classical compiler data flow analyses to reveal properties of data flow in cognitive models that are useful to cognitive scientists such as detecting computational clones to enable reusability of models. Distill identifies computational clones in different cognitive models to enable reuse or substitution of complex models by simpler ones. Distill is publicly available, integrated with the PsyNeuLink cognitive modeling environment, and is already being used by researchers in the brain sciences.
Distill also repurposes classical compiler data flow analyses to reveal properties of data flow in cognitive models that are useful to cognitive scientists such as detecting computational clones to enable reusability of models. Distill identifies computational clones in different cognitive models to enable reuse or substitution of complex models by simpler ones. Distill is publicly available, integrated with the PsyNeuLink cognitive modeling environment, and is already being used by researchers in the brain sciences. Paper:
Ján Veselý, Raghavendra Pradyumna Pothukuchi, Ketaki Joshi, Samyak Gupta, Jonathan D. Cohen, and Abhishek Bhattacharjee. 2022. Distill: domain-specific compilation for cognitive models. In Proceedings of the 20th IEEE/ACM International Symposium on Code Generation and Optimization (CGO '22). IEEE Press, 301–312. https://doi.org/10.1109/CGO53902.2022.9741278